
SQL Server 아키텍쳐(Architecture) 구성에 대해 이해하고자 정리하였습니다.
SQL Server 프로세스는 클라이언트 응용 프로그램이 요청을 보내는 것으로 시작되며 처리된 데이터에 대한 요청을
수락, 처리 및 응답합니다.
아래 다이어그램은 SQL Server 아키텍쳐의 세 가지 주요 구성 요소를 보여줍니다.
1. 프로토콜 계층(Protocol Layer)
2. 관계형 엔진(Relational Engine)
3. 저장 엔진(Storage Engine)

프로토콜 계층(Protocol Layer)
SNI(SQL Server Network Interface)
MS SQL Server 프로토콜 계층은 3가지 유형의 클라이언트 서버 아키텍쳐를 지원합니다.
1. 공유메모리(Shared Memory)
Tom과 엄마의 대화 시나리오를 가정하여 설명하겠습니다. ▼

Tom과 그의 엄마는 똑같은 논리적인 장소인 집에 있습니다.
Tom은 커피를 요청할 수 있고, 엄마는 커피를 뜨겁게 제공할 수 있습니다.
여기서 MS SQL Server는 공유 메모리 프로토콜(Shared Memory Protocol)을 제공합니다.
클라이언트와 MS SQL 서버는 동일한 시스템에서 실행되며 둘 다 공유 메모리 프로토콜을 통해
통신할 수 있습니다.
위의 시나리오를 엔터티에 매핑하면 톰은 Client, 엄마는 SQL Server로 Home to Machine 및 Verbal
Communication은 공유 메모리 프로토콜이 됩니다.
구성 & 설치 참고사항
로컬 DB 연결의 경우 - SQL Management Studio에서 "서버 이름" 옵션은
"."
"localhost"
"127.0.0.1"
"Machine/Instance"
로 설정이 가능합니다.
SQL Server가 설치된 서버를 클라이언트로 사용하는 경우
기본적으로 공유 메모리 프로토콜을 사용하여 인스턴스에 연결을 시도합니다.

2. TCP/IP
Tom은 저녁에 파티 분위기에 있다고 가정하여 설명하겠습니다. ▼

Tom은 스타벅스에서 주문한 커피를 먹고 싶으며 스타벅스는 그의 집에서 10km 떨어져 있습니다.
즉, Tom과 스타벅스는 서로 다른 물리적 위치에 있으며 셀룰러 네트워크를 통해 통신하고 있습니다.
마찬가지로,
MS SQL Server는 TCP/IP 프로토콜을 통해 상호 작용할 수 있는 기능을 제공합니다.
여기서 클라이언트와 MS SQL 서버는 원격이며 별도의 시스템에 설치됩니다.
위의 시나리오를 엔터티에 매핑하면 Tom은 Client, 스타벅스는 SQL Server, Home/Market은 원격지,
셀룰러 네트워크는 TCP/IP가 된다.
구성 & 설치 참고사항
TCP/IP를 통한 연결의 경우 "서버 이름" 옵션은 "서버의 컴퓨터/인스턴스" 이어야 하며
SQL Server는 TCP/IP에서 포트 1433을 사용합니다.

3. Named Pipe
Tom은 이웃인 Sierra가 타주는 녹차를 마시고 싶다는 가정으로 설명하겠습니다. ▼

Tom과 Sierra는 같은 동네에 살고 있으며 인트라넷을 통해 상호작용 하고 있습니다.
클라이언트와 SQL Server가 LAN을 통해 연결된 경우
Named Pipe 프로토콜을 통해 상호작용을 할 수 있습니다.
위의 시나리오를 엔터티에 매핑하면 Tom은 Client, Sierra는 SQL Server,
인트라넷은 Named Pipe Protocol이 된다.
구성 & 설치 참고사항
이 옵션은 기본적으로 비활성화되어 있으며, SQL 구성 관리자에서 활성화 해야 합니다.
관계형 엔진(Relational Engine)
관계형 엔진은 쿼리 프로세서라고도 하며 스토리지 엔진에서 데이터를 요청하고 반환된 결과를 처리하며
사용자 쿼리 실행을 담당합니다. 세가지 주요 구성요소로 구분할 수 있습니다.
1. CMD Parser
CMD Parser는 프로토콜 계층에서 수신된 사용자 쿼리를 수신하는 관계형 엔진의 첫번째 구성 요소입니다.
주요 작업은 사용자 쿼리의 구문 및 의미 오류를 검증하고 쿼리트리를 생성합니다.
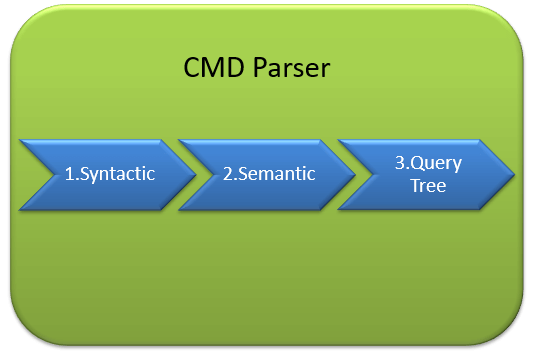
[ 구문검사 ]
MS-SQL에는 사전 정의된 키워드 세트가 있으며 독자적인 문법이 존재합니다.
( SELECT, INSERT, UPDATE 및 기타 다수 등)
CMD Parser는 구문 검사를 수행하고 쿼리 데이터가 문법 규칙을 따르지 않으면 오류를 반환합니다.
가장 기본적인 쿼리 구문은 다음과 같습니다.
SELECT * FROM <Table Name>;
다음과 같이 오타가 발생한 기본 쿼리를 실행하면
<Table Name>의 SELECR *
CMD Parser는 쿼리에 대한 구문 분석하고 오류 메세지를 표시합니다.
"SELECR"은 미리 정의된 키워드 이름과 문법이 아니기 때문입니다.
[ 의미검사 ]
노멀 라이저(Normalizer)에 의해 수행되며 가장 간단한 형태로 스키마(Schema)에 Column명, Table명 등이
존재하는지 확인 후 존재하는 경우 쿼리에 바인딩(Binding)합니다.
주의사항으로 쿼리 데이터에 뷰(View)가 포함되면 복잡성이 증가합니다.
SELECT * FROM USER_ID
CMD 파서는 의미 검사를 위해 쿼리 데이터를 분석하고 요청된 테이블(USER_ID)이 존재하지 않는 경우
구문 분석기는 오류 메세지를 표시합니다.
[쿼리트리]
이 단계는 쿼리를 실행할 수 있는 별도의 쿼리트리를 생성하며 동일한 사용자 쿼리로 생성된 쿼리트리는
동일한 결과값을 가집니다.
2. 옵티마이저(Optimizer)
옵티마이 작업은 사용자 쿼리에 대한 실행 또는 계획을 만드는 것입니다.
이것은 사용자 쿼리를 실행되는 방법을 결정합니다.
모든 쿼리가 최적화 되는 것은 아니며 SELECT, INSERT, DELETE 및 UPDATE와 같은 DML(Data Modification
Language) 구문만 최적화가 수행됩니다.
CREATE 및 ALTER와 같은 DLL 명령은 최적회되지 않지만 내부 형식으로 컴파일됩니다.
쿼리 비용은 CPU 사용량, 메모리 사용량 및 입/출력 요구 기반으로 계산됩니다.
옵티마이저의 역할은 가장 저렴하고 효율적인 실행계획을 찾는 것 입니다.
MS-SQL 옵티마이저는 내장된 exhaustive/heuristic 알고리즘에서 작동합니다.
최적화 검색은 아래 다이어그램과 같이 세 단계를 따릅니다.

0단계 : 일반적인 계획 검색
0 단계는 사전 최적화 단계라고하며 일반적인 알려진 실용적이고 실행 가능한 계획이 한가지 CASE만
존재하는 경우 적용되며 추가비용을 방지할 수 있습니다. 어떤 계획도 찾을 수 없는 경우 1단계로 넘어갑니다.
1단계 : 트랜잭션 처리 탐색 계획
1단계는 단순 및 복합 계획 검색이 포함됩니다.
단순 계획 검색은 쿼리에 관련된 컬럼 및 인덱스의 과거 데이터를 통계 분석에 사용합니다.
단순 계획으로 최적화가 되지 않으면 복합 계획 검색을 시작합니다.
2단계) : 병렬 처리 및 최적화
위 단계에서 어느 것도 적용되지 않으면 옵티마이저는 병렬 처리 가능성을 검색합니다.
병렬처리로 최적화가 되지 않는 경우 가능한 다른 모든 옵션을 찾는 최종 최적화 단계가 시작됩니다.
3. 쿼리 실행기(Query Executor)
쿼리 실행기는 옵티마이저에서 생성한 실행 계획을 이용하여 실행에 필요한 데이터 가져오기 로직에 대한
실행 계획을 제공합니다. 스토리지 엔진에서 데이터를 수신하면 결과가 프로토콜 계층으로 전달됩니다.

저장 엔진(Storage Engine)
스토리지 엔진에는 세 가지 구성 요소가 있으며 스토리지 엔진의 작업은 디스크 또는 SAN과 같은 스토리지
시스템에 데이터를 저장하고 필요할 때 데이터를 검색합니다.

<데이터 파일 및 범위>
데이터 파일은 데이터 페이지의 형태로 데이터를 저장하며 크기는 8kb입니다.
데이터 페이지는 논리적으로 그룹화되어 익스텐트를 형성합니다.
페이지에는 메타 데이터 정보를 전달하는 96byte 크기의 페이지 헤더라는 섹션이 있습니다.
(페이지 유형, 페이지 번호, 사용된 공간 크기, 다음 페이지 및 이전 페이지에 대한 포인터 등)

<파일 유형>
(1) 기본 파일 : *.mdf
모든 데이터베이스에는 하나의 기본 파일이 있으며 테이블, 뷰, 트리거 등과 관련된 모든 중요한
데이터를 저장합니다.
(2) 보조 파일 : *.ndf
보조파일은 선택사항으로 데이터베이스는 여러 개의 보조 파일을 포함할 수 있습니다.
(3) 로그 파일 : *.ldf
트랜잭션 관리에 사용되는 파일로 원치 않는 인스턴스에서 복구하는데 사용됩니다.
커밋되지 않은 트랜잭션으로 롤백하는 중요한 작업을 수행합니다.
1. 접근 방법(Access Methods)
사용자 쿼리에 따라 액세스 방법은 아래 단계를 수행합니다.
- SELECT 쿼리는 추가처리를 위해 버퍼 관리자로 전달됩니다.
- DDL, NON-SELECT 쿼리는 트랜잭션 관리자로 전달됩니다.
여기에는 대부분 UPDATE 문이 포함된다.

2. 버퍼 관리자(Buffer Manager)
버퍼 관리자는 아래 모듈의 핵심 기능을 담당합니다.
· 계획 캐시
· 데이터 파싱
· 더티 페이지

(1) 계획 캐시
버퍼 관리자는 저장된 계획 캐시에 실행 계획이 있는지 확인하고 쿼리 계획 캐시 및 관련 데이터 캐시를
사용합니다.
(2) 데이터 파싱
(버퍼 캐시 및 데이터 저장)
버퍼 관리자는 필요한 데이터에 대한 액세스를 제공합니다.
데이터 캐시 존재유무에 따라 다음 두 가지 접근 방식이 가능합니다.
(2-1) 버퍼 캐시-소프트 구문 분석
데이터 캐시에서 버퍼의 데이터를 찾고 캐시가 존재하는 경우 쿼리 실행기에서 반영합니다.
데이터 저장소에서 데이터를 가져오는 것과 비교하여 I/O 작업 수가 줄어들기 때문에 성능이 향상됩니다.

(2-2) 데이터 스토리지-하드 파싱
데이터 캐시에 필요한 데이터가 없는 경우 데이터 저장소에서 데이터를 검색하고 나중에 사용하기 위해
데이터 캐시에 데이터를 저장합니다.

(3) 더티 페이지
트랜잭션 관리자의 처리 로직으로 저장됩니다.
3. 트랜잭션 관리자
트랜잭션 관리자는 액세스 방법이 Query가 Non-Select 문이라고 판단 할 때 호출됩니다.

(1) 로그 관리자(Log Manager)
로그 관리자는 트랜잭션 로그의 로그를 통해 시스템에서 수행된 모든 업데이트를 추적합니다.
로그에는 트랜잭션 ID 및 데이터 수정 레코드가 있는 로그 시퀀스 번호가 있으며 커밋된 트랜잭션 및
트랜잭션 롤백을 추적하는데 사용됩니다.
(2) 잠금 관리자(Lock Manager)
트랜잭션 중 데이터 저장소의 관련 데이터는 잠금 상태로 전환됩니다.
이 프로세스는 데이터의 일관성과 격리를 보장하며 ACID 속성이라고도 합니다.
실행 프로세스
로그 관리자는 로깅을 시작하고 잠금 관리자는 관련 데이터를 잠금 상태로 전환합니다.
데이터 사본은 버퍼 캐시에 보관되며 업데이트될 데이터의 사본은 로그 버퍼에 보관되고 모든 이벤트는
데이터 버퍼의 데이터를 업데이트합니다.
데이터를 저장하는 페이지는 더티 페이지(Dirty Pages)라고도 합니다.








최근댓글